One Patch to Caption Them All: A Unified Zero-Shot Captioning Framework
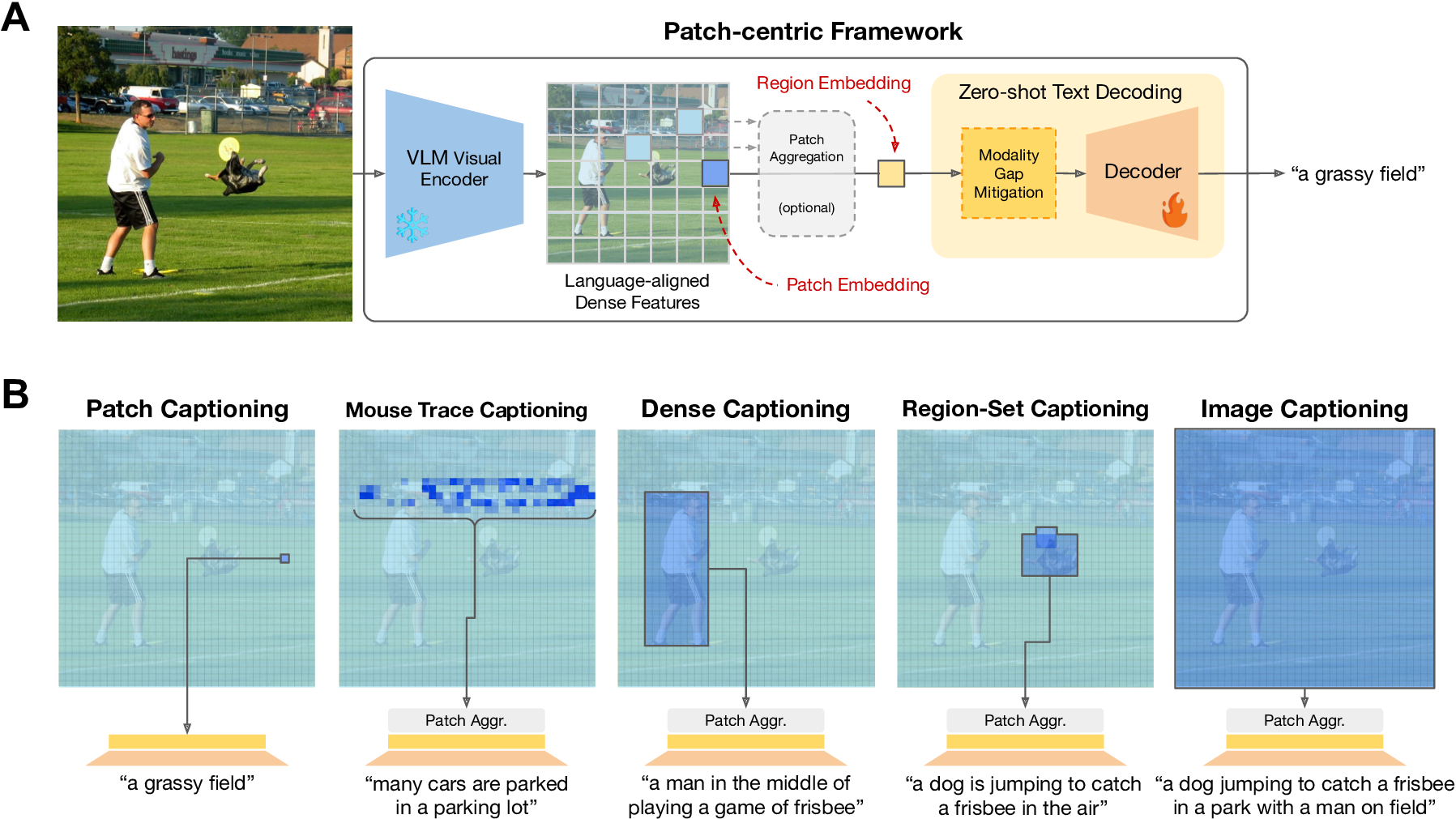
Zero-shot captioners are recently proposed models that utilize common-space vision-language representations to caption images without relying on paired image-text data. To caption an image, they proceed by textually decoding a text-aligned image feature, but they limit their scope to global representations and whole-image captions.
We present Patch-ioner, a unified framework for zero-shot captioning that shifts from an image-centric to a patch-centric paradigm, enabling the captioning of arbitrary regions without the need of region-level supervision. Instead of relying on global image representations, we treat individual patches as atomic captioning units and aggregate them to describe arbitrary regions, from single patches to non-contiguous areas and entire images.
We analyze the key ingredients that enable current latent captioners to work in our novel proposed framework. Experiments demonstrate that backbones producing meaningful, dense visual features, such as DINO, are key to achieving state-of-the-art performance in multiple region-based captioning tasks. Compared to other baselines and state-of-the-art competitors, our models achieve better performance on zero-shot dense, region-set, and a newly introduced trace captioning task, highlighting the effectiveness of patch-wise semantic representations for scalable caption generation.