How to create a database of thousands of users in a couple of hours
When you realize a new application it is fundamental to populate its database with data, so that the first users coming will not find an empty page.
This situation is often called cold start, and should always be avoided or mitigated in some way.
When I faced cold starts
Many of the services that I developed needed for data to be used for the first time; for example dronesimulator could not be published before writing many simulation questions, or traveltales needed news as sources to generate custom radio feeds.
But there is a case in which this process required me much more work, which is MappIt.
Preventing the MappIt cold start
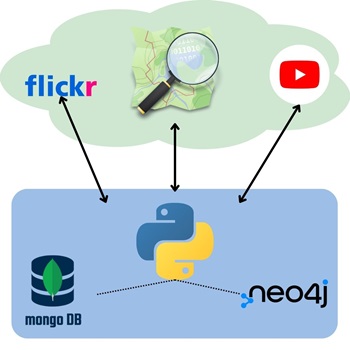
For the deployment of the MappIt service I was searching for a dataset with all the required structures and information, or way to fetch those kind of data from external service.
The kind of data that I needed to gather were:
- a set of places, each of them with its name, coordinates and an image
- a set of posts, which must be relative to the aforementioned places. Each post must be done by an author, must contain at least an image and possibly a link to a YouTube video, and also a title and a description of the post
- a set of users, that should be the authors of the posts
Since I was not able to find anything online with all the characteristics above, I decided that I have to implement a data seeder from scratch for MappIt.
Choosing data sources
Places
Generating places is a process characterized by low velocity (in the sense that new places can come very rarely, and then this process can be scheduled once every year), and we can also observe that it is not necessary to dispose of a variety of data sources for this process, assuming that all the places are basically the same of the ones exposed by other sources.
For the places collection I choose to adopt the data exposed by OpenStreetMap, which can be accessed through the Overpass API, which is a read-only API that serves up custom selected parts of the Open Street map data. It is possible to specify several search criteria like e.g., location, type of objects, tag properties, proximity, or combinations of them.
Overpass QL (short for “Overpass Query Language”) is a procedural, imperative programming language for querying the Overpass API.
Here it is an example of query, which aim is to retrieve all the historical nodes and ways in Italy with some exceptions for the value of the attribute historic:
[out:json];
area["ISO3166-1:alpha2"="IT"]->.searchArea;
(
node["historic"]["historic"!~"cannon|charcoal_pile|boundaray_stone|city_
gate|creamery|farm|gallows|highwater_mark|milestone|optical_telegraph|pa|r
ailway_car|rune_stone|vehicle|wayside_cross|wayside_shrine|yes"]["name"](a
rea.searchArea);
way["historic"]["historic"!~"cannon|charcoal_pile|boundaray_stone|city_g
ate|creamery|farm|gallows|highwater_mark|milestone|optical_telegraph|pa|ra
ilway_car|rune_stone|vehicle|wayside_cross|wayside_shrine|yes"]["name"](ar
ea.searchArea);
);
out body center meta;
>;
out skel qt;
out center meta;
For every place obtained by this query, I loaded an image to associate with it by a wikipedia API that lets you gather wikipedia page details for a specified wikipedia page id. The wikipedia page id was returned by the Overpass API when available.
Posts
To create the Post dataset, I adopted two different sources to increase the variety: YouTube for videos and Flickr for images. Both platforms provide APIs to collect information like title, author, description, publication date, etc.
As the dataset velocity is higher than the places’ velocity, I assumed that a routine runs periodically to update Post dataset with new videos and images from the same sources, and I implemented a method to run that.
The search phases in the FlickR and YouTube APIs are performed place by place, exploiting as search parameter the place coordinates and the place name, so that only the posts made on FlickR and YouTube geo-referenced to the places are reported.
In the MappIt project documentation you can find the complete execution logic of these steps.
Users
The users are generated starting from the posts, and in particular I implemented a method that, given a YouTube account ID, returns the MappIt acccount associated with it, either by creating it from zero or either loading it from the database. I did the same also for Flickr.
User details like email and birthdate are generated by exploiting the Faker library.
Generation of social network relations
I also implemented a method that receives as parameter the ID of a user for which it will generate social relations.
The relations that it will generate are:
- LIKE
- FOLLOWS
- FAVOURITES
- VISITED
The number of relations generated is a random number between a minimum and a maximum threshold.
This method by default is called every time that a new user entity is generated.
Managing redundancies and cross-database entities and relations
Since, as more thoroughly exposes in its project page, MappIt is a service that exploits two kinds of databases, one documental and the other a graph-based database, the data population procedures must be in charge also of handling the storage of information in the two systems.
The creation of a new place, for example, not only consists in inserting a document in MongoDB, but also a node in Neo4j, while the generation of social relations mainly consists in accessing the Neo4j entities. By the way there are some redundancies, like for example the total likes counter, that are cross-database.
Those redundancies were designed in order to improve the execution time of frequent database operations, but can introduce inconsitencies of the data.
In order to restore eventual inconsistencies that could verify, I implemented the redundancies updater procedure, which is responsible to update the redundancies counters that we inserted in the documents of some entities in Mongo like the field “likes” in the Post documents, the field “followers” in the User documents or the fields “favourites” and “totalLikes” in the Place documents.
The update of these redundancies is needed only when a user, all the posts of a user, or a post are deleted from the application, because the consistency in this case is demanded to this procedure, to prevent too much load on the server for the entities’ deletion. This procedure is scheduled weekly.
Controlling the data population module
The data population module ended up being complex and articolated, and exposes many different methods and possibilities.
In order to have control over them I implemented a command prompt, whose available methods are:
- generate posts: the available parameters for this command are:
- YouTube specify this parameter to make the application perform a query over YT Data API
- Flickr specify this parameter to make the application perform a query over Flickr API
- –num use this parameter to specify the maximum number of places on which the search must be performed
- update-redundancies: this method forces the run of the procedure of redundancies updating
- generate places: this method executes the search_and_parse method of OsmPlaceFactory using the area specified as parameter
Note: the command “generate posts” by default loads 10 places for each post source, ordered by ascending value of LastSearch.
Periodically fetching new posts
Since the procedures are all accessible as commands of the prompt script, it is possible to schedule the periodic execution of a command in crontab with a specific period.
What I did was to schedule weekly this command in crontab:
python dataPopulation.py generate posts youtube flickr –all-places
Conclusions
In this post I reported an example of a (complicated) data seeding script that I had to implement for one of my projects.
Often the data accessible in a service at its launch is fundamental for its success, and this is why it is important to know how to populate an application database, in particular it is necessary to spend the right amount of time in the design of this aspect and to take the right decisions for the selection of the data sources.
MappIt data seeder is Open Source
If you want to get more details and go deeper in the details of my implementation of the data population script for MappIt, you can have a look at the code and test it by yourself, since it is open source: MappIt data seeder repo.
If you have further questions on the topic, contact me.